1. Overview
1.1 CPU and GPU
CPU与GPU结构对比图
![]()
GPU适合运算密集(compute-intensive)的数据并行(data-parallel)程序。
- 运算密集:算数操作(arithmetic operation)的比例要远大于内存操作(memory operation),因此内存访问的延时可以被计算掩盖,而不需要CPU结构下的大Cache。
- 数据并行:对每个数据块执行相同的指令,因此对复杂流程控制的需求较低。
1.2 Scalable Programming Model
当我们有了多核CPU或者多核GPU后,接下来需要让我们开发的程序能够处理的数据规模自动地随着核数的增长而增长。
CUDA提供了三个关键的抽象,线程组、共享内存、Barrier同步。
在这样的抽象下,对于一个任务,我们首先将其粗粒度地分为互相独立的子任务,子任务由一个线程块(thread block)完成,一个线程块有多个线程,线程块内的线程之间可以进行同步。
由于各个线程块互相独立,因此可以任意顺序地执行,所以一个CUDA程序可以在任意核的GPU上运行,且随着核数的增加,其耗费的时间也会自动地减少,如下图。

2. Programming Model
2.1 Kernels
Kernels是CUDA C对C的扩展,首先看如下代码。
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
使用__global__关键字声明一个Kernel
VecAdd就是一个Kernel
通过<<< >>>语法调用Kernel,VecAdd实际会有N个线程运行,在Kernel函数内,可以通过访问threadIdx获得线程编号
上面的代码将A和B两个数组的各个元素相加并将结果存储到C中
2.2 Thread Hierarchy
threadIdx是一个三维的向量,如下代码计算矩阵A和矩阵B的和,并将结果存于C中
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
由于一个线程块内的所有线程运行在同一个处理器核心上,且共享该核心的有限的存储资源,线程块内的线程数量是有限制的,当前的GPU上,可能最多只能有1024个线程
前面提到在Kernel中我们可以通过访问threadIdx获得线程ID,类似地,在Kernel中我们可以通过访问blockIdx获得线程块ID
如下的代码,计算矩阵A和矩阵B的和,并将结果存于矩阵C中,并且这份实现中使用了多个线程块
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
重申一下:线程块之间必须独立
线程块内的线程可以通过共享内存分享数据,为了保证内存的正确访问,当然也可以进行同步操作
为了有效率地协同运行,线程块内的共享内存的访问速度相当于一级缓存,同步操作也是轻量级的
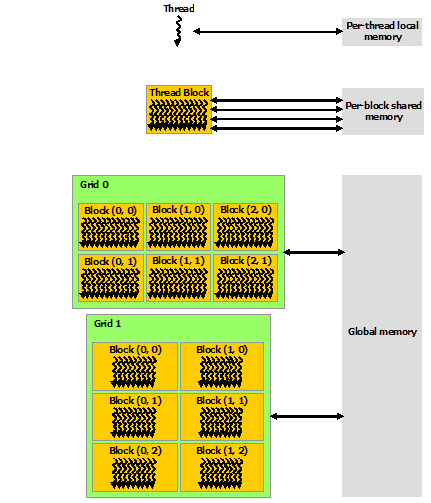
2.3 Memory Hierarchy
每个线程有其专有内存,每个线程块也有其专有内存让块内线程共享访问,所有的线程同时可以访问一个全局内存,如图
2.4 Heterogeneous Programming
对于一个CUDA程序,其Kernel运行在GPU上,其余部分运行在CPU上
